Building microservices with Micronaut (Part II)
The second post around microservices with Micronaut framework will explore distributed configuration, distributed tracing and server side events
![]()
We will pick it up from where we left in our previous post. We used a beer bar context to introduce our microservices.
A bar tender service which is ready to serve beers to multiple customers and get track of the costs to prepare the customer bill once our customer asks for it.
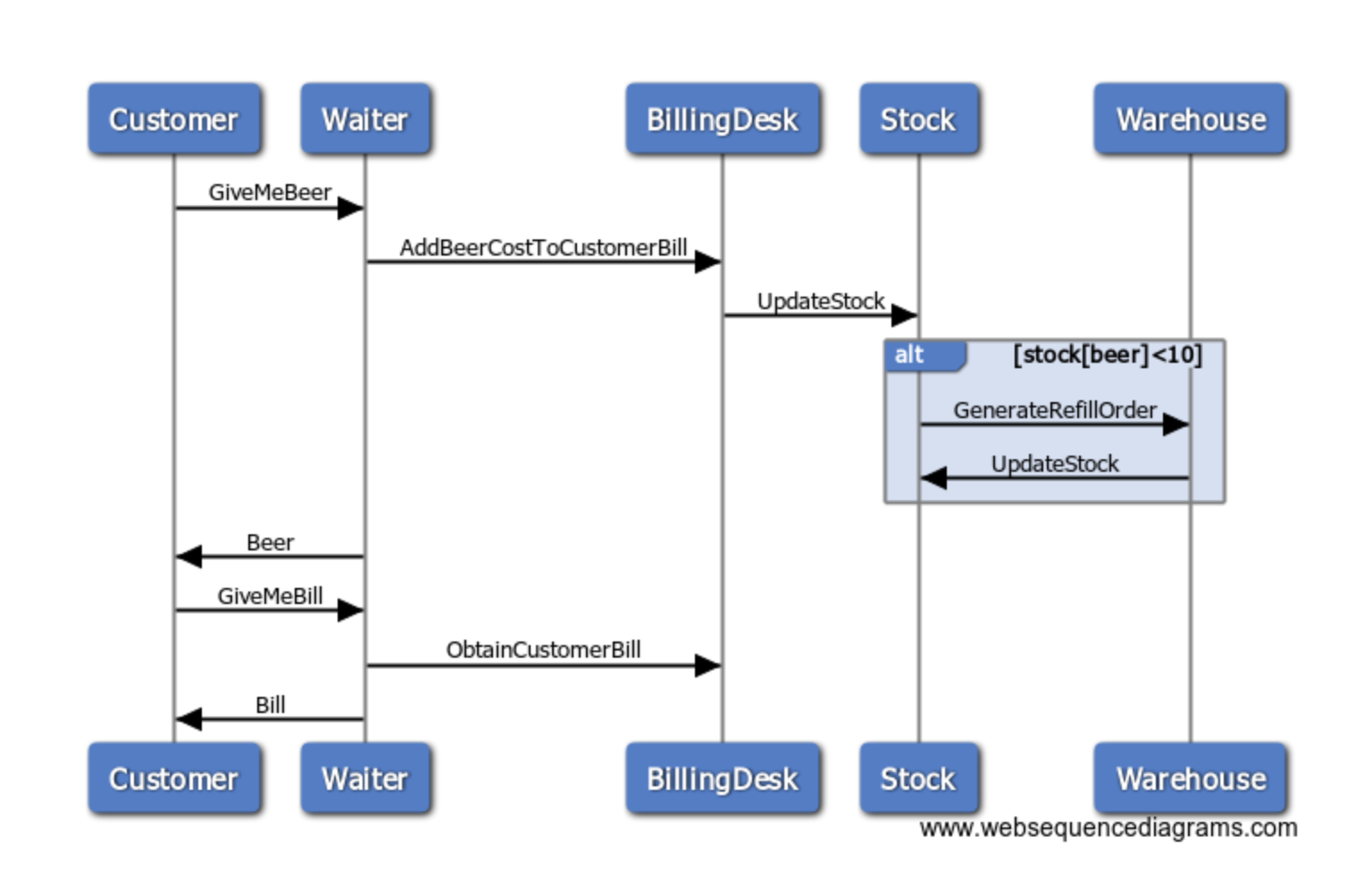
If you remember we introduced some awesome annotations, it was a that piece of cake to enable common or frequent microservices patterns like service registry and discovery, circuit breaker and retry
We will evolve our code to add more features and see more Micronaut framework in action.
DISTRIBUTED CONFIGURATION
If you are a developer you have faced multiple times the dilemma of designing components of your system that can be flexible enough to cope with future changes.
Probably you have defined a set of properties or configuration values that define the behaviour of your components. Most of the times those configuration values are related with the coordinates of servers with their ports, usernames and passwords (those should be encrypted!), endpoint paths, database or queue names, topics, you name it. In other occasions you may have list of predefined values that are not worthy to persist in the database or you feel lazy enough to do it. Yes everyone has been there…
Trying to remember the approaches anyone could chose in the old times in the Java world these were my options
- Using JNDI resources
Yes, it was a thing when you were handling App Servers like BEA Weblogic, Tomcat or any App Server. I think it did not get too much traction, because no one wanted to be the admin of the app server.. so luckily now we tend to use from that path.
- Using properties files
It’s one of the most common approaches with many sub-variants .. shall I use a plain key value list, or xml.. ..or yaml. Should the application detect whenever the file changes to reload its properties or shall I Implement something behind the scenes? What about a observer pattern? What happens to the beans that were initialized with a value and suddenly that value is not valid any longer? Micronaut supports obviously this approach nicely and has some nice feature that allow mapping entries on your file directly with the attributes of your bean.
- Using environment variables
According to the 12 Factor method this is the way to go.
And I guess their statement is right, mainly because environment variables are easy to changes across environments, there is no need of restart as far as you sync the values often. Another important bit is that no matter which language we use they way to access to their value is pretty straightforward.
Now that we have Configuration Management tools like Puppet, Chef or Ansible, etc it’s really easy to automate the creation of variables organized in several modules / recipes.
- Using database
It may seem a bit overwhelming, but there are certain values that fit well on these mechanism.
Those days where I had the “cap” of Vignette CMS expert, I’ve seen everything to be treated as an object that could be edited and published. And yes configuration was one of the most important objects in our cms. Stored as Json or XML we kept values that allowed to modify completely layout of the website/pages/areas. We could flip feature flags to enable/disable specific behaviour that allowed us to test features for specific users or regions, timeouts, servers, credentials, A-N-Y-T-H-I-N-G.
However release management was very,v ery tricky. It was extremely difficult to track if changes to a property were required because they were not under SCM like Git/SVN. Changes were done in the database, and releases had to be carefully crafted to be sure those database values where moved or recreated (in case there were environmental dependencies like servers ,etc). Also in order to “move” properties across different stages (DEV, QA, TST, Live, ..) we had to think on tools to allow incremental export/import of properties everytime we did a release. So you can see that it was “kind-of-painful” ..
- Using a configuration repository
I stumbled upon Spring Configuration Server and I really enjoyed seeing how with the right structure you could manage the configuration of your system using just Git and a set of files. Those files values were injected directly in our Java beans and defining the @Refresahble scope you could define “hooks” that will update automatically the value of your member attribute whenever the file was commited/pushed against the repo.
With the arrival of microservices, in a IOT world heavily interconnected via REST API (http, grpc) or Messaging protocols, chosing the right configuration mechanism is key to success. And here is where our Framework takes an opinionated approach that works nicely.
Are not our configuration properties just a set of key text and values? Why not using either etcd or Zookeper which keeps the K/V store in a distribited environment? Hang on a minute… In the previous blog entry we used Consul for Service Discovery and Registration of our microservices. In case you were not aware it bring out of the box a KV store too with an API easy to integrate with.
We will explore in our example both support of Properties files and also using Consul to see how distributed configuration works out of the box. Let’s get back to our example.
First we will add some more features to our ticket billing service. In our initial version we had the cost of each beer defined as hardcoded values depending on the size of the beer, within our BeerItem POJO.
We will refactor a bit in order to introduce a interface CostCalculator, that will be responsible of calculating the price. Our cost calculation will be based on defining the base for small beer and apply a multiplier depending on the size. We will also consider adding VAT taxes. Our beer will be now a bit more expensive, buhhhhh ! … but that gives me a chance to see how can we wire everything configuring those values in our Consul Key Value store.
A few changes are necessary in our controller, so Micronaut can inject a candidate bean for CostCalculator. As we have only one no-constructor implementation is trivial, In case we had more than one implementation, we should use Qualifiers and javax.annotation.Named to do the matching. Our controller now looks like (removing non-related bits to the change)
@Controller("/billing")
@Validated
public class TicketController {
HashMap<String, Ticket> billsPerCustomer = new HashMap<>();
final EmbeddedServer embeddedServer;
final CostCalculator beerCostCalculator;
@Inject
public TicketController(EmbeddedServer embeddedServer,
CostCalculator beerCostCalculator) {
this.embeddedServer = embeddedServer;
this.beerCostCalculator = beerCostCalculator;
}
.........
@Get("/cost/{customerName}")
public Single<Double> cost(@NotBlank String customerName) {
Optional<Ticket> ticket = Optional.ofNullable(billsPerCustomer.get(customerName));
double cost = ticket.isPresent() ? beerCostCalculator.calculateCost(ticket.get()) :
beerCostCalculator.calculateCost(getNoCostTicket());
return Single.just(Double.valueOf(cost));
}
.........
private Ticket getNoCostTicket() {
BeerItem smallBeer = new BeerItem("Korona", BeerItem.Size.EMPTY);
Ticket noCost = new Ticket();
noCost.add(smallBeer);
return noCost;
}
}
Now let’s wire the properties to our Bean that implements the interface we need. Using @Value annotations we can wire properties regardless which is its source (environment properties, files, etc)
public class BeerCostCalculator implements CostCalculator {
@Value("${beer.base.cost.value}")
private int beerBaseCost =1;
@Value("${vat.value}")
private int vat ;
public int getVat() {
return vat;
}
public void setVat(int c) {
this.vat = c;
}
public int getBeerBaseCost() {
return beerBaseCost;
}
public void setBeerBaseCost(int c) {
this.beerBaseCost = c;
}
public double calculateCost(Ticket ticket) {
return allBeersCost(ticket)*(1+vat/100);
}
private double allBeersCost(Ticket ticket) {
return ticket
.getBeerItems()
.stream()
.map( beer -> calculateBeerCost(beer))
.mapToDouble(i->i).sum();
}
private double calculateBeerCost(BeerItem beer) {
switch (beer.getSize()) {
case SMALL : return 1* beerBaseCost;
case MEDIUM: return 2* beerBaseCost;
case PINT: return 3* beerBaseCost;
case EMPTY: return beerBaseCost;
default: return 99;
}
}
}
As we want Micronaut to retrieve those values from a Consul configuration server, we need to add more changes. It took me a while to find out that our application configuration now will be scattered across 2 files. Distributed Configuration is enabled adding a new file bootstrap.yml
micronaut:
application:
name: billing
config-client:
enabled: true
consul:
client:
defaultZone: "${CONSUL_HOST:localhost}:${CONSUL_PORT:8500}"
Our configuration application.properties must be as follows.
micronaut.application.name=billing
consul.client.registration.enabled=true
consul.client.config.enabled=true
consul.client.config.format=properties
consul.client.defaultZone=${CONSUL_HOST:localhost}:${CONSUL_PORT:8500}
Before we proceed be sure your consul instance started.
docker run -p 8500:8500 consul
Based on the value micronaut.application.name , we will add the values of our properties using the path “config/billing” using Consul API. You can observe how the names match with the @Value annotations we added in our BeerCostCalculator bean. Let’s add a 21% VAT and the minimum service fee cost to be 1.
curl -X PUT -d @- localhost:8500/v1/kv/config/billing/vat.value <<<21
curl -X PUT -d @- localhost:8500/v1/kv/config/billing/beer.base.cost.value <<<1
If we start our application and we ask for the cost of any user we expect to receive 1.21 (service fee + vat) even if the user did not get a beer yet.
If I start our application and call directly to the endpoint
>> curl http://localhost:36940/billing/cost/zzz
1.21
When combining @Value with a Configuration Server like Consul, the changes to the properties in Consul are not propagated automatically to the beans that reference them.
We can only force it using the /refresh endpoint that would reload all the beans annotated with Refreshable.
Micronaut could benefit if a mechanism is in place in order to subcsribe to events Consul changes, in order to perform the same action, without the need of hitting the refresh endpoint.
As usual Graeme was very helpful in the Micronaut Gitter channel, and he explained that there are a plans to do that and he suggested to raise a feature request to track this change.
DISTRIBUTED TRACEABILITY
With the proliferation of microservices, observability and traceability it’s every time more important. The higher number of microservices your solution is made of, the more important becomes to be able to trace end to end a request and its flow across different components in your system.
When you have a mess of services communicating and depending on each other is fundamental to know on real time, why this service failed, how long did it take to perform this request, detect critical paths, learn where are significant delays on processing, in summary help to understand the behaviour of your architecture. Some of them could be solved just with scaling, others will be solved with a redesign of components, but without having a clear view on the issues and how the information flows from service A to Z, there is no way you can tacklet the issue.
There are hyper-simple approaches that may work using correlation-ids that are propagated across services. If you combine that with a Log agregator at least you can trace request, timings ,etc but is still based on text log files difficult to troubleshoot. You can do that in old monolithic applications or system where two or three components are involved. But if you start adding more components you will end in a “search-grep-log-hell” nightmare, hopefully I’m not the only one who has ever been there, right?
But really we are here to see how Micronaut can help in this subject by providing specific modules and anotations to integrate either with Zipkin (created by Twitter based on Dapper) or Jaeger (opensourced by Uber) which are the most popular distributed tracing solutions. I’ve chosen Zipkin, but reading the documentation, the steps are quite similar if you prefer to do it with Jaeger.
First we enable tracing by adding the dependency in our pom.xml file
<dependency>
<groupId>io.micronaut</groupId>
<artifactId>tracing</artifactId>
<scope>compile</scope>
</dependency>
Our application properties file needs to include the following settings
tracing.zipkin.enabled=true
tracing.zipkin.http.url=http://localhost:9411
tracing.zipkin.sampler.probability=1
The last bit would anotate our code to enable tracing. Zipkin is based on OpenTrace, so it’s a good oportunity to introduce the newbies to the concept of Span. “note-to-self: I’m also a newbie here!”
A span can be identified by its name and contains metadata about start time and duration. We can either start new spans or add new spans to the existing ones. We can create a hierarchy of parent-child spans that will allow fine grain traceability.
With the addition of zipkin instrumenting libraries we can reach low level detail like http, jdbc, etc. You can imagine you will be interested on knowing the steps your request went through after hitting the controller, the service and the underlying data access layer.
In Java world Zipkin uses Brave behind the scenes which provides instrumentation on different protocols (http, rpc,grpc) or messaging systems like RabbitMq or Kafka. The full list can be found here.
We will trace first a couple of method calls in our TicketController.
In our example we will refactor a bit the way we track our bills by creating a proper service instead of keeping just a simple Map.
We are interested in knowing when the request arrives, so we start tracing at log level every new span, and provide information about the metadata as far as it steps trough different methods/layers.
The Span annotations @NewSpan or @ContinueSpan stick to the OpenTrace standard so we can create new or continue an existing one. Usign @SpanTag we can add extra metadata related with our parameters.
Our ticket controller now creates new span for each of the entry points. Also we are instructing our code so the private methods contribute to our span.
@Get("/bill/{customerName}")
@NewSpan("bill")
public Single<Ticket> bill(@NotBlank String customerName) {
Optional<Ticket> t = getTicketForUser(customerName);
Ticket ticket = t.isPresent() ? t.get() : new Ticket();
ticket.setDeskId(embeddedServer.getPort());
return Single.just(ticket);
}
@Get("/cost/{customerName}")
@NewSpan("cost")
public Single<Double> cost(@NotBlank String customerName) {
Optional<Ticket> t = getTicketForUser(customerName);
double cost = t.isPresent() ? beerCostCalculator.calculateCost(t.get()) :
beerCostCalculator.calculateCost(getNoCostTicket());
return Single.just(Double.valueOf(cost));
}
@ContinueSpan
private Ticket getNoCostTicket() {
BeerItem smallBeer = new BeerItem("Korona", BeerItem.Size.EMPTY);
Ticket noCost = new Ticket();
noCost.add(smallBeer);
return noCost;
}
@ContinueSpan
private Optional<Ticket> getTicketForUser(@SpanTag("getTicketForUser") String customerName) {
return Optional.ofNullable(billService.getBillForCostumer(customerName));
}
This configuration is enough to see that the creation of traces is happening locally. I had to enabled trace level in the package “io.micronaut.tracing”.
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<!-- encoders are assigned the type
ch.qos.logback.classic.encoder.PatternLayoutEncoder by default -->
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="debug">
<appender-ref ref="STDOUT" />
</root>
<logger name="io.micronaut.tracing" level="TRACE"/>
</configuration>
Starting our server and hitting some of the endpoints we can see in the log span creation:
13:38:01.988 [nioEventLoopGroup-3-4] TRACE i.m.t.b.log.Slf4jCurrentTraceContext - Closing scope for span: 7d87c72616e5f50c/fd0f27942edfc46d
13:38:01.988 [nioEventLoopGroup-3-4] TRACE i.m.t.b.log.Slf4jCurrentTraceContext - Closing scope for span: 7d87c72616e5f50c/fd0f27942edfc46d
13:38:01.988 [nioEventLoopGroup-3-5] TRACE i.m.t.b.log.Slf4jCurrentTraceContext - Starting scope for span: 7d87c72616e5f50c/fd0f27942edfc46d
13:38:01.989 [nioEventLoopGroup-3-5] TRACE i.m.t.b.log.Slf4jCurrentTraceContext - With parent: 9045417343003784460
13:38:01.989 [nioEventLoopGroup-3-5] TRACE i.m.t.b.log.Slf4jCurrentTraceContext - Starting scope for span: 7d87c72616e5f50c/fd0f27942edfc46d
13:38:01.989 [nioEventLoopGroup-3-5] TRACE i.m.t.b.log.Slf4jCurrentTraceContext - With parent: 9045417343003784460
13:38:01.989 [nioEventLoopGroup-3-5] TRACE i.m.t.b.log.Slf4jCurrentTraceContext - Closing scope for span: 7d87c72616e5f50c/fd0f27942edfc46d
13:38:01.989 [nioEventLoopGroup-3-5] TRACE i.m.t.b.log.Slf4jCurrentTraceContext - Closing scope for span: 7d87c72616e5f50c/fd0f27942edfc46d
Ok, it seems first step was accomplished. However we are more interested in sending those spans “somewhere” so we can query them and see the output and analyze results.
We can enable distributed tracing with Zipkin just adding some dependencies on our pom.xml
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave-instrumentation-http</artifactId>
<version>4.19.0</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>io.zipkin.reporter2</groupId>
<artifactId>zipkin-reporter</artifactId>
<scope>runtime</scope>
<version>2.5.0</version>
</dependency>
<dependency>
<groupId>io.opentracing.brave</groupId>
<artifactId>brave-opentracing</artifactId>
<scope>compile</scope>
<version>0.30.0</version>
</dependency>
Now we enable configuration in our bootstrap.yml file.
micronaut:
application:
name: billing
config-client:
enabled: true
consul:
client:
defaultZone: "${CONSUL_HOST:localhost}:${CONSUL_PORT:8500}"
tracing:
zipkin:
enabled: true
http:
url: http://localhost:9411
sampler:
probability: 0.1
A couple of notes about sampling. The configuration is only taking 10% of the request to be processed by Zipkin. If you want to change the value you can scale it up to 1 which is 100% but in a real production system, that could be overwhelming.
Also worth mentioning after inspecting the source code, we can use multiple Zipkin servers using the property http.urls .Micronaut performs client load balancing sending requests in a round robin fashion.
We will repeat exactly the same steps on the other Waiter microservice. I will omit the details as are identical, quick summary: add all POM dependencies, check your bootstrap.yml file and add the span annotations to our controller.
@Controller("/waiter")
@Validated
public class WaiterController {
TicketControllerClient ticketControllerClient;
public WaiterController(TicketControllerClient ticketControllerClient) {
this.ticketControllerClient = ticketControllerClient;
}
@Get("/beer/{customerName}")
@NewSpan
public Single<Beer> serveBeerToCustomer(@NotBlank String customerName) {
Beer beer = new Beer("mahou", Beer.Size.MEDIUM);
BeerItem beerItem = new BeerItem(beer.getName(), BeerItem.Size.MEDIUM);
ticketControllerClient.addBeerToCustomerBill(beerItem, customerName);
return Single.just(beer);
}
@Get("/bill/{customerName}")
@NewSpan
public Single<CustomerBill> bill(@NotBlank String customerName) {
Single<Ticket> singleTicket = ticketControllerClient.bill(customerName);
Single<Double> singleCost= ticketControllerClient.cost(customerName);
Ticket ticket= singleTicket.blockingGet();
CustomerBill bill = new CustomerBill(singleCost.blockingGet().doubleValue());
bill.setDeskId(ticket.getDeskId());
return Single.just(bill);
}
}
The easiest way is starting a local instance with docker.
docker run -d -p 9411:9411 openzipkin/zipkin
Now let ‘s spin up both services. Remember that our Waiter calls our Ticket service whenever users wants a beer or request the bill.
John arrives to the bar, VERY thirsty and ask for 5 beers, one after another, pays the bill and then leave our bar a bit happier and tipsy:
for i in `seq 1 5`;do
curl "http://localhost:8082/waiter/beer/john"
done
#reply for each beer
{"name":"mahou","size":"MEDIUM"}
{"name":"mahou","size":"MEDIUM"}
{"name":"mahou","size":"MEDIUM"}
{"name":"mahou","size":"MEDIUM"}
{"name":"mahou","size":"MEDIUM"}
curl "http://localhost:8082/waiter/bill/john"
#cost of 5 beers + vat + service fees
{"cost":12.1,"deskId":16983}
We can open now Zipkin console and see some interesting stuff. We can see that we can filter by service as both services Waiter and Ticket have been tracing their spans.
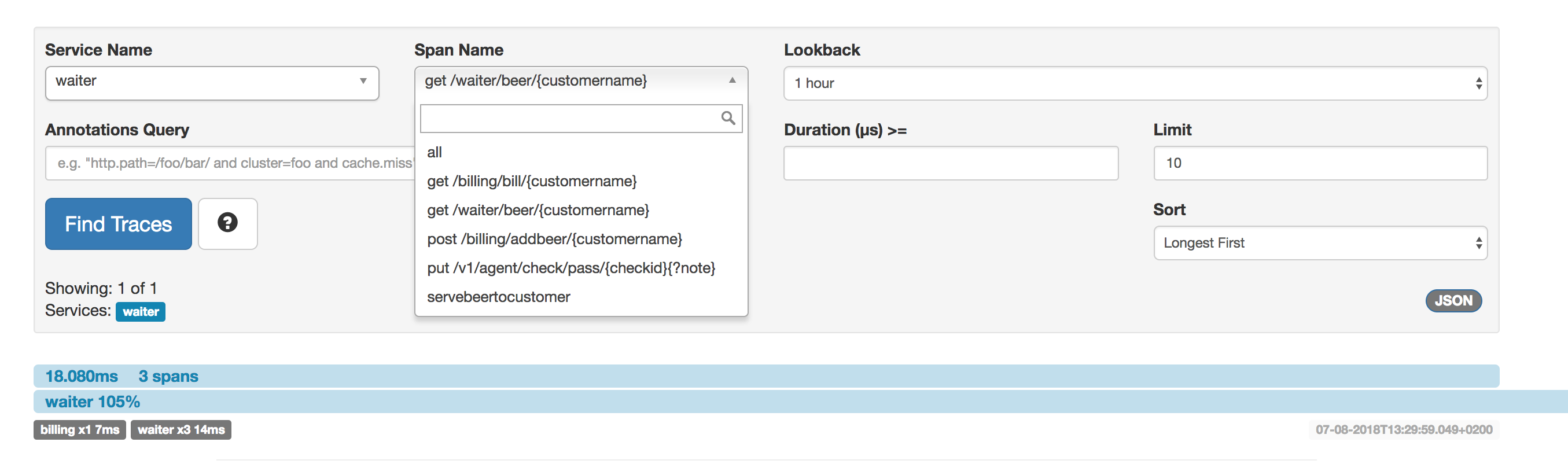
We can chose Waiter and drill down further down. We can inspect what happened when John asked for one of the beers. We can see there are 3 spans, with its timing.
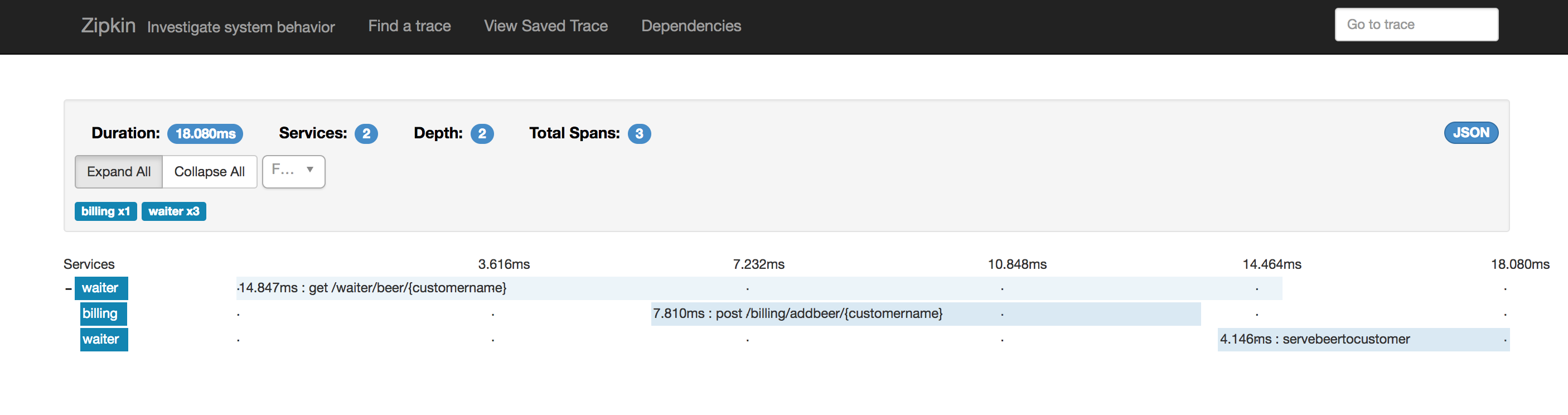
The first one due to the http instrummentation itself, the second one due to the anotation we added in our controller and the third one shows the interaction via the POST call done by our Waiter using the Client interface that Micronaut generated automatically with the @Client annotation. Is not it neat?
Browse within Zipkin console to the Dependencies, we can see that Waiter depends on billing service. It may seems trivil in this example, but when you have 50 microservices with one-to-one request-response, reactive response or via async queue I guarantee you that having a clear mindmap on how your services speaks among them is paramount to understand your architecture.
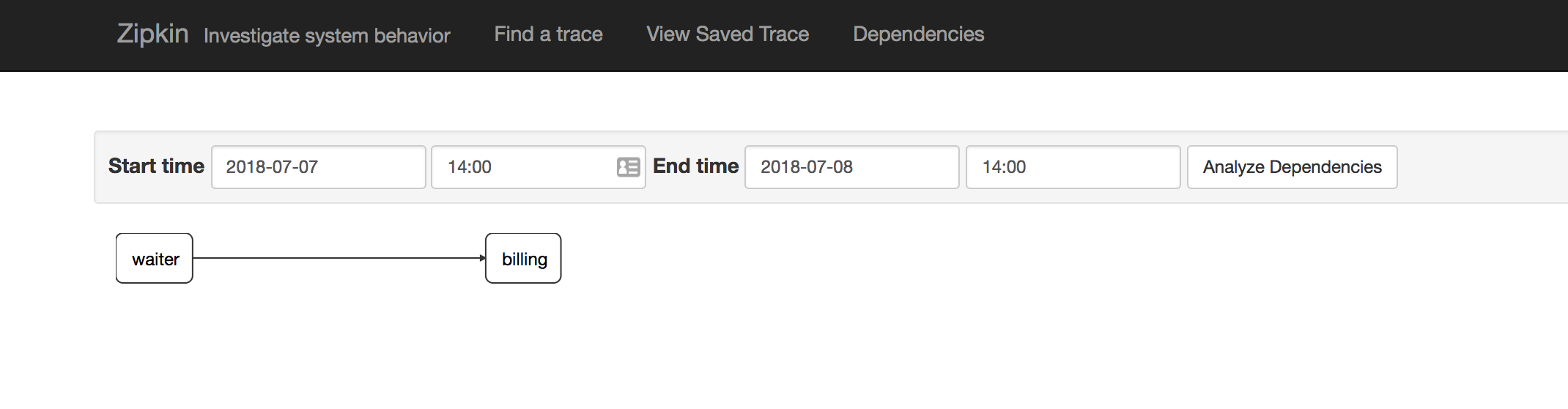
STREAMING EVENTS
Nowadays we see that REST APIs, show syncronous communication patterns where we can disect the flow a request-response approach. Every request is processed by the server and returned in a (hopefully) timely fashion to the client, using HTTP codes to indicate whether request was processed succesfully or not.
The raise of Single Page Aplications who need to refresh its state frequently brings another approach where continuous polling is not longer an option. Although some one may still see it as an option, we should encourage anyone trying to use due to the unnecessary overhead that the server needs to deal with and the excesive network traffic originated by this approach.
I played a while ago with server side push frameworks like Comet Server in Play. Those were the times of early servlet specificications ranging from 2.3 to 2.5. Then the new 3.1 Servlet specification (JSR 340) opened new posibilities and servlet implemented websockets. We later started to hear about NIO, Netty Async, etc. I personally did some websocket work for a customer in NodeJs in 2012, but since then I did not hget my hands dirty with it again.. till today.
Let’s consider for a moment, that we want to know at any time how many users are in our awesome bar. But instead of doing a request-response approach we want to monitor how our beloved customers join our bar. This is a perfect candidate for server side streaming. We could complicate things a bit, and now exactly how much each of them has spent till that very moment, so would be the perfect tool for a manager who wants to supervise incomes on real time.
Micronaut promises easy event streaming just by returning data of a specific Publisher
We will add a new endpoint to our TicketController. It will deliver a message saying how many people do we have in our bar, together with our customer names.
Please notices that we added MediaType.TEXT_EVENT_STREAM as media type so we can deliver over http, continuously.
@Get(uri = "/users", produces = MediaType.TEXT_EVENT_STREAM)
Publisher<Event<String>> users() {
return Flowable.generate(() -> 0, (i, emitter) -> {
if (i < 100000) {
Thread.sleep(1000);
int howManyUsers = billsPerCustomer.size();
String message = billsPerCustomer.keySet().stream().collect(Collectors.joining(","));
if (howManyUsers==0) {
emitter.onNext(Event.of("The bar is empty!"));
} else {
emitter.onNext(Event.of("The bar has " + howManyUsers + " users: " + message));
}
} else {
emitter.onComplete();
}
return ++i;
});
Let’s start first ONLY our Ticket Billing service. If we hit the url we will a message saying see that no users have arrived yet. No surprises here. Our waiter is a lazy bozy and did not make it on time.
>> curl http://localhost:1239/billing/users/
The bar is empty!
The bar is empty!
The bar is empty!
.......
The bar is empty!
Now let’s wake up our waiter. Apparently some guys want some beers! After spinning up our Waiter service, we will simulate people drinking activity.Each of them will ask for a beer.
#wait a few secs
curl http://localhost:8082/waiter/beer/mauricio
#wait a few secs
curl http://localhost:8082/waiter/beer/amanda
#wait a few secs
curl http://localhost:8082/waiter/beer/john
We can observe the results directly on our browser over HTTP. Observe the HTTP is never interrupted and the stream data keeps coming ( See network traffic time)
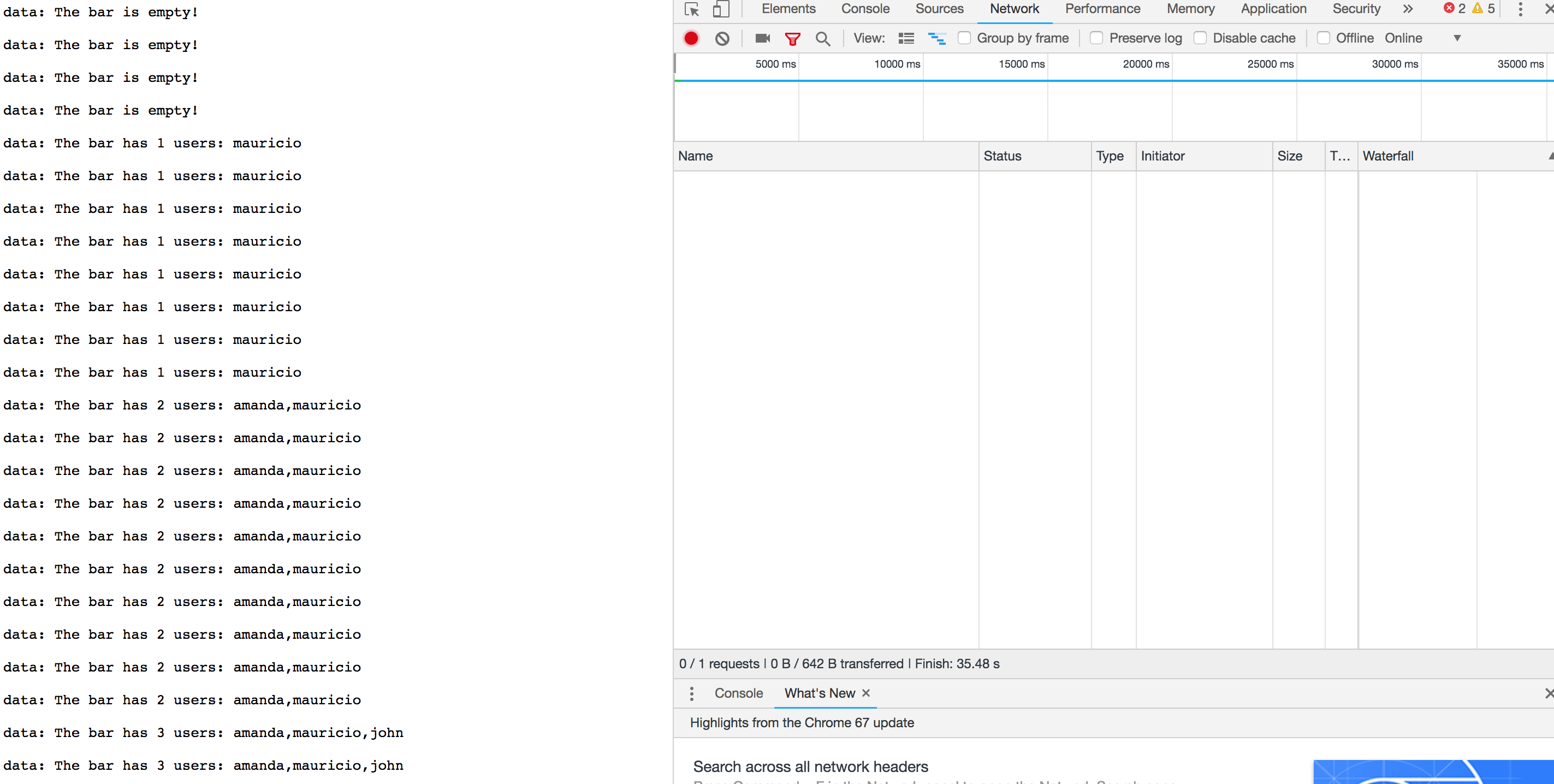
I hope you enjoyed some of the features Micronaut brings to developers.
To finish the Micronaut series, I will write another post focusing only on how Micronaut enables integration with Serverless Functions.