s3 storage service - aws certification exam tips concepts

In case you are thinking on passing the aws solutions architect exam these notes are a quick summary on some of the basic s3 concepts you would need to be familiar with.
s3 is AWS Storage as a a service with high availability (99,99) and durability(11 9’s).
It’s s glorified key value store where the key is the name of the object itself.
Buckets and objects.
A bucket can be seen as a top folder structure.
- Bucket acts as a container of objects. We can nest objects , those could be either subfolders or files.
- Creation of buckets must adhere to DNS standards , universal namespace. It must be unique across aws
- Buckets can be attached only to one region and cannot be switched afterwards.
- Buckets cannot be removed if there are objects within the bucket.
- There is no limit on the number of objects within a bucket.
- Object are a key value store where the key is the name of the object itself.
- Objects can store up to 5TB. Zero bytes objects are totally valid!
- Objects can be locked to prevent an object from being deleted or overwritten for a fixed amount of time or indefinitely.
Consistency
-
S3 buckets provide strong read after create consistency (new objects). However the eventual consistency happens when updating an objet or deleting it.
-
The data is spread across multiple devices and facilities for high-availability or disaster recovery. So once you update an object it may transcur a few seconds till the changes are propagated across different Availability Zones(AZ).
Clarification: If we chose storage class Infrequent access with a single zone, there is no eventual consistency as there is no need to replicate across any AZ
Security
-
By default every bucket is configured to be not public.
-
Other levels of security can be achieved using ACL’s (Acces control lists), but AWS suggest is better to use S3 Bucket policies. For shake of clarity - what is an S3 ACL? A set of AWS accounts can be configured identifying permission for list / write / read at bucket and object level.
-
The most common way is by defining a S3 Bucket Policy which enable more granular permissions based on conditions and resources which are attached only to S3 buckets. S3 bucket policies specify what actions are allowed or denied for which principals on the bucket that the bucket policy is attached to.
Versioning
-
It can be enabled at bucket level. From that moment onwards, any object that is created or updated will have an objectVersionId. Versioning allow us to see history of changes and revert to a previous version.
-
Once versioning is activated in a bucket, we cannot remove it totally so the objects that were versioned in the past would remain versioned.
-
However we can suspend versioning at any time. In that case new objects or future modification on existing objects which will not have the versioning metadata anymore.
Encryption
There are several encryption mechanisms that can be configured at bucket or object level
- Amazon S3-managed keys (SSE-S3)
- AWS Key Management Service (AWS KMS)
- Customer master keys (CMKs).
Encryption happens before is stored in disk and decrypted when downloaded. An alternative to this approach is encrypt at request time, by adding headers on our request
Management
There are several storage tiers
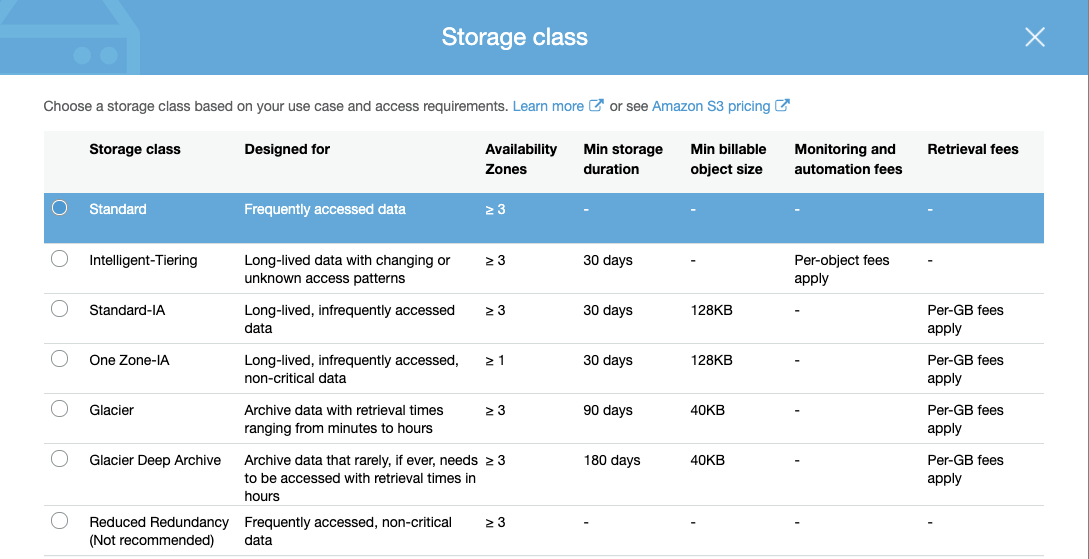
-
We can define lifecycle rules that determine when our object can transit to a different storage tier It’s useful for expiration of content, archiving old content, or moving less frequent accessed content to tiers which are cheaper than the standard one.
-
Chosing a cheaper tier, you may expect slower access times while retrieving your objects. For example if we archive using Glacier we would talking about hours till our documents are available.
Cross replication
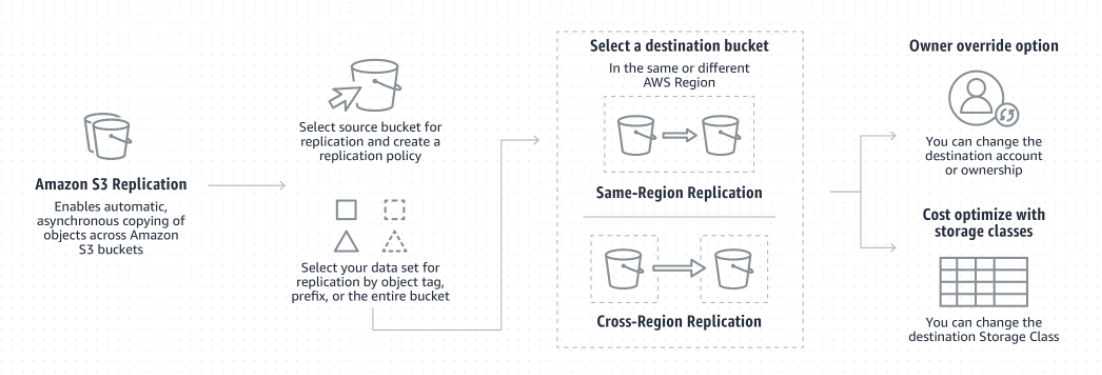
- Cross replication enable to select different replication across buckets within the same region or different regions.
- It could be unidirectional or in both ways.
- Only S3 buckets with Versioning turned on, will enable cross-region replication.
- The sync process is asyncronous and is worthy mention that although the source and target objects of the replica are identical, each bucket could be configured differently in terms of underlying storage classes.
- Keep an eye on costs, (double storage)
Posible use cases could be: a simple backup, delivery of data to different aws accounts.
Downloading
We mentioned that is a good practice to restrict access to your buckets, so in order to share our docs there are a few options
- make the bucket/object public
- enable a bucket policy allowing specific permissions on actions like getObject
- Generate a presigned url which will give temporary access to the s3 resource. Presigned links expire according to how they were generated.
S3 Acceleration Transfer
-
If we plan to be uploading big files we should consider using s3 accelerated transfers via CloudFront’s edge locations. The approach takes benefit of the internal AWS network backbone,routing data to your s3 bucket destination using the fastest/optimal path.
-
It allows egress/ingress traffic speed increase (50%-300%) faster.
S3 access points
Once I stumbled with this concept I did not fully get it… Why do we need this if we already can access programatically via sdk and restrict access with great level of granularity?
In the security section we described how S3 Bucket policies can be used to protect access to our buckets. In many situations that is enough, however in big corporative environments whith multiple roles and access patterns, this could be difficult to managed. Imagine granularity at user level, in a big organization where maybe even segregating users by role groups would become a nightmare.
- S3 access points are simple network endpoints over a bucket.
- They can be opened to the internet but we can also configure the endpoints with restrictions on VPC Let’s imagine we have EC2 in a VPC and we want to be sure that S3 bucket is only accessed through from there. Instead of messing with policies, we restrict access to the endpoint based on the VPC / Subnet where the EC2 instance is attached.
Other interesting use cases with S3 in the AWS echosystem
- We can create a website fully with S3 and simply create a Cloudfront using S3 as origin.
- We can read data from S3 , using AWS Glue and then run SQL queries on this data in Athena.
- Select from : For S3 objects we can extract records from a single CSV, JSON or Parquet file using SQL expressions
- We can wire s3 events with other s3 services such as SNS, SQS or Lambda whenever CRUD operations occur on s3 objects.
Using S3 events with SNS
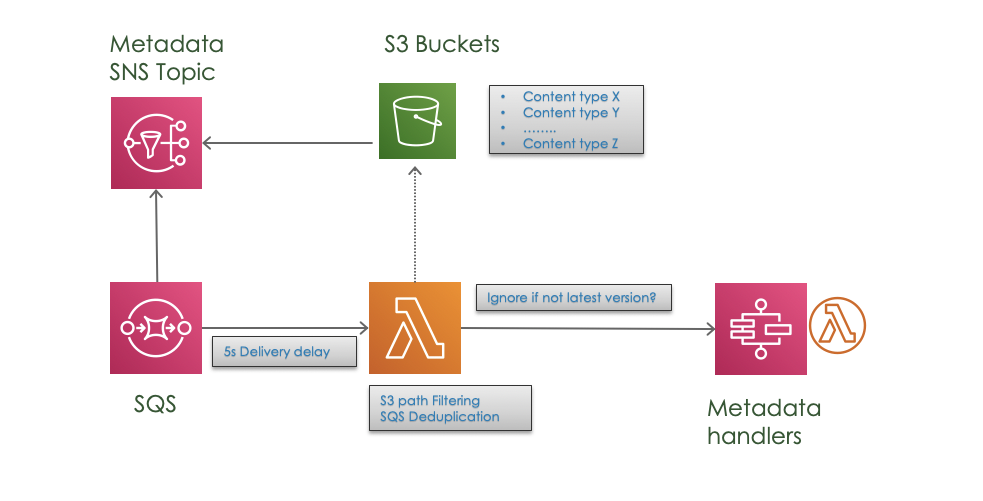
I will ellaborate a bit more on this point sharing our experience from last project.
It’s very common integration patters when building serverless event driven solutions, to trigger a lambda function, but instead of triggering directly a lambda is also recommeded to use a SNS topic, in case you may benefit from multiple suscribers.
Some decisions were taken in order to cope with some small challenges
- Eventual consistency
It may take a while till the object is replicated across every AZ. Luckily enough for us our S3 events arrive via SNS topic, so we could put a SQS reader with a 5 second delay to guarantee that once we go to the bucket the document is there.
Additionally we used versioning metadata as a “belt and braces” approach. It’s a common pattern to process s3 events and retrieve its metadata afterwards. We re using S3 Standard across multiple AZ’s. Therefore there is no guarantee that once we call the getObject (latest) function we retrieve exactly the same document that was source of our event. This is due to the eventual consistency across AZ’s. Also we do not know if maybe other writer created a new version different to our version.
With “Versioning” enabled, we receive the versionIdentifier as part of the event, which help us to know exactly which is the right object to retrieve.
-
Adding SQS to the picture, dictates that we potentially need to face possible duplicated messages(Due to SQS distributed nature, it follows a delivery “at least once”, but could be more than one)
-
Noise in the SNS topic. The source of event were all the subfolders of a specific bucket. There were many irrelevant events. The solution is based on s3 filtering of events based on its path.