Query S3 json with Athena and AWS Glue
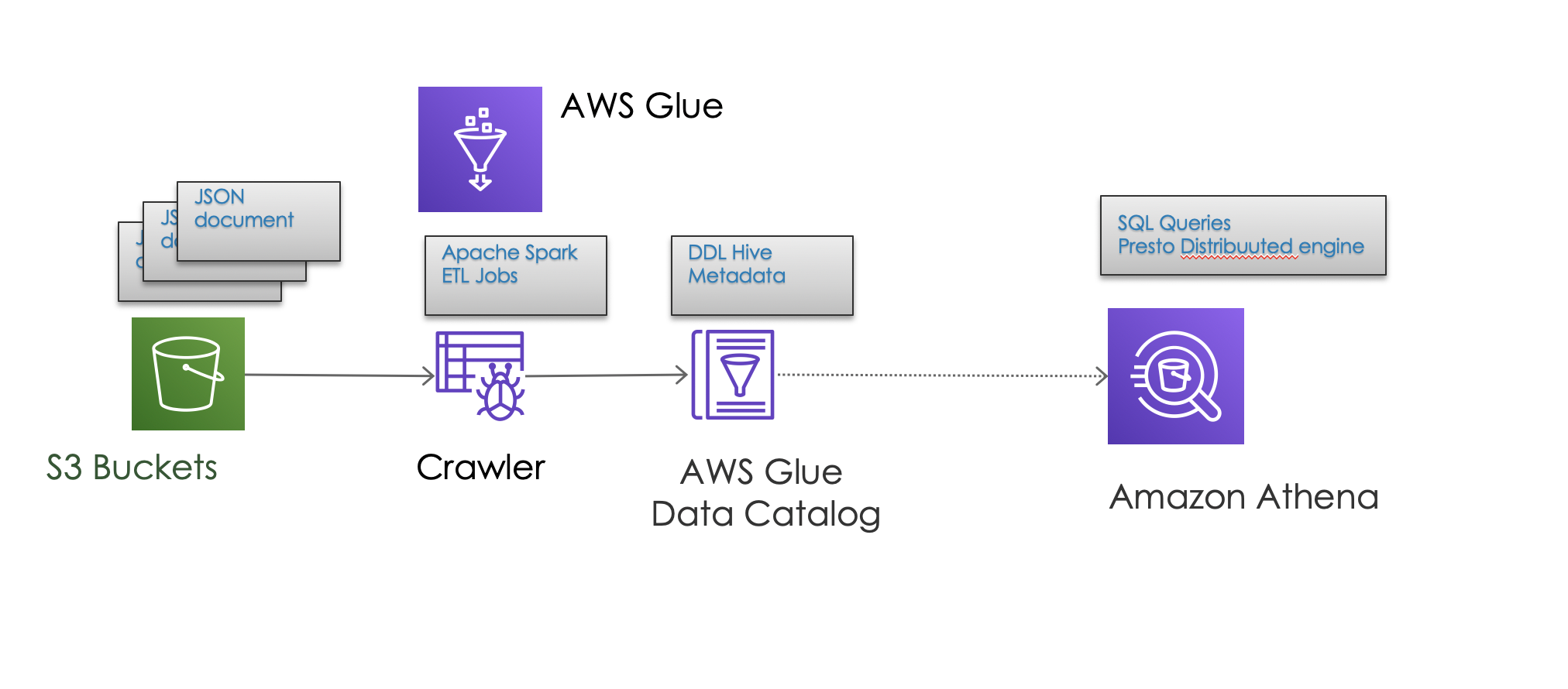
We will describe how we can create tables which read data from S3 so we can perform queries on those metadata.
AWS Athena and AWS Glue to the rescue!
What is Athena ?
Athena enable to run SQL queries on your file-based data sources from S3. Business use cases around data analysys with decent size of volume data make a good fit for this.
We could also provide some basic reporting capabilities based on simple JSON formats.
Behind the scenes Athena uses Presto (open sourced by Facebook) as distributed SQL engine and Apache Hive DDL syntax to create, drop, and alter tables and partitions.
What is AWS Glue?
AWS Glue Catalog allow us to define a table pointing to our S3 bucket so it can be crawled.
It’s a ETL engine that uses Apache Spark jobs and Hive metaddata catalog fully managed service.
We can define crawlers which can be schedule to figure out the struucture of our data. We will end up with a metadata table in the catalog describing that data. Metadata will be used by Athena to query your data.
When should we use it?
There are scenarios where we are not interested on having a full blown database, for example those information silos or enterprise data lakes where analytics processing need to be done.
Considering that S3 is extremely cheap, we will see show how quick we can turn a bucket into a source of information for our business queries without having to worry about adding some RDS stack or NoSql solution to our architecture.
If we were handling tons of data the first thing to reconsider is the format. Instead of JSON we could use Parquet which is optimized columnar format easier to compress and query results are much faster. I will let the reader to explore that option ;)
If you do not want to query the data yourself there are out of the box integration with your favourite BI provider ( Tableau, Microsoft Power Bi, etc) and obviosly the one from AWS (Amazon QuickSight)
Create a bucket in S3
The bucket will contain the objects, over which we will be performing our queries.
In our case we will be dropping full JSON objects. But we could have chosen CSV files in case we want to process multiple data rows.
This is an extract of JSON object I dropped. It represents an episode from Game of thrones.
{
"releaseYear": 2019,
"active": true,
"name": "Game of thrones - Season 8",
"shortSynopsis": "Jon and Daenerys arrive in Winterfell and are met with skepticism. Sam learns about the fate of his family. Cersei gives Euron the reward he aims for. Theon follows his heart.",
"duration": "PT55M",
"title": "Winterfell",
"availabilityStartAt": "2020-05-13T10:20:00.000Z",
"availabilityStartAt": "2020-07-13T10:20:00.000Z"
}
Create a workgroup
Using AWS Athena you need to select a workgroup or create a new one.
Create a database
Using AWS Glue you can create a database, which simply requires a name. Let’s name it “sample_db”
Create a table
Using AWS Glue you can create a table using the UI:
Navigate to : Databases > Tables > Add Tables
You need to enter
- Table name and its database “sample_report_table” within the “sample_db”
- Select a datasource , which in our case is the s3 url of the bucket Glue supports other sources like Kafka or Kinesis which are out of the scope of this post
- Format: Multiple formats are supportedsuch as Avro, XML, JSON, CSV, Parquet We need to chose JSON for ouur example.
- Schema: You need to add one by one the columns and types for your table If the JSON document is complex, adding each of the columns manually could become a cumbersome task.
It’s way more effective using directly the Aws Athena interface. Athena provides a SQL-like interface to query our tables, but it also supports DDL(Data definition language)
So we can simple execute this create statement where we define directly how our columns look like and how are they populated from the JSON document.
If we focus on the top level metadata fields from the JSON document a trivial setup would be:
CREATE EXTERNAL TABLE IF NOT EXISTS sample_db.sample_report_table (
`name` string,
`shortSynopsis` string,
`availabilityStartAt` string,
`availabilityEndAt` string,
`duration` string,
`title` string
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'case.insensitive'='false',
'mapping.name'='name',
'mapping.shortSynopsis'='shortSynopsis',
'mapping.availabilityStartAt'='availabilityStartAt',
'mapping.availabilityEndAt'='availabilityEndAt',
'mapping.duration'='duration',
'mapping.title'='title'
) LOCATION 's3://mysample-poc-athena/'
TBLPROPERTIES ('has_encrypted_data'='false')
In case your JSON fields have camelCase names, then use ‘case.insensitive’=’true’, otherwise fields like shortSynopsis will return empty metadata.
The table will keep a row per each JSON object we have in S3.
The mapping provide is trivial, but it support much more complex configuration like defining struct types that match with nested json objects, or data arrays , etc.
Querying data
SELECT * FROM "sample_db"."sample_report_table" limit 10;
If you get your results nicely formatted that is all you need to start querying data!
NOTE: If you stumble with error feedback from UI console such as:
HIVE_CURSOR_ERROR: Row is not a valid JSON Object - JSONException: A JSONObject text must end with '}' at 2 [character 3 line 1]
Review your JSON file in S3. It’s very important the file is in a single line, no EOL characters or anything …otherwise you will be banging your head as I did till I found this valuable link: https://aws.amazon.com/premiumsupport/knowledge-center/error-json-athena/