Apply CQRS pattern to build microservice with Micronaut and Kafka
The following post would describe a basic CQRS framework implementation using Micronaut. Micronaut helps us to create Kafka producers and consumers that we will use as a way to communicate events.
Introduction to CQRS
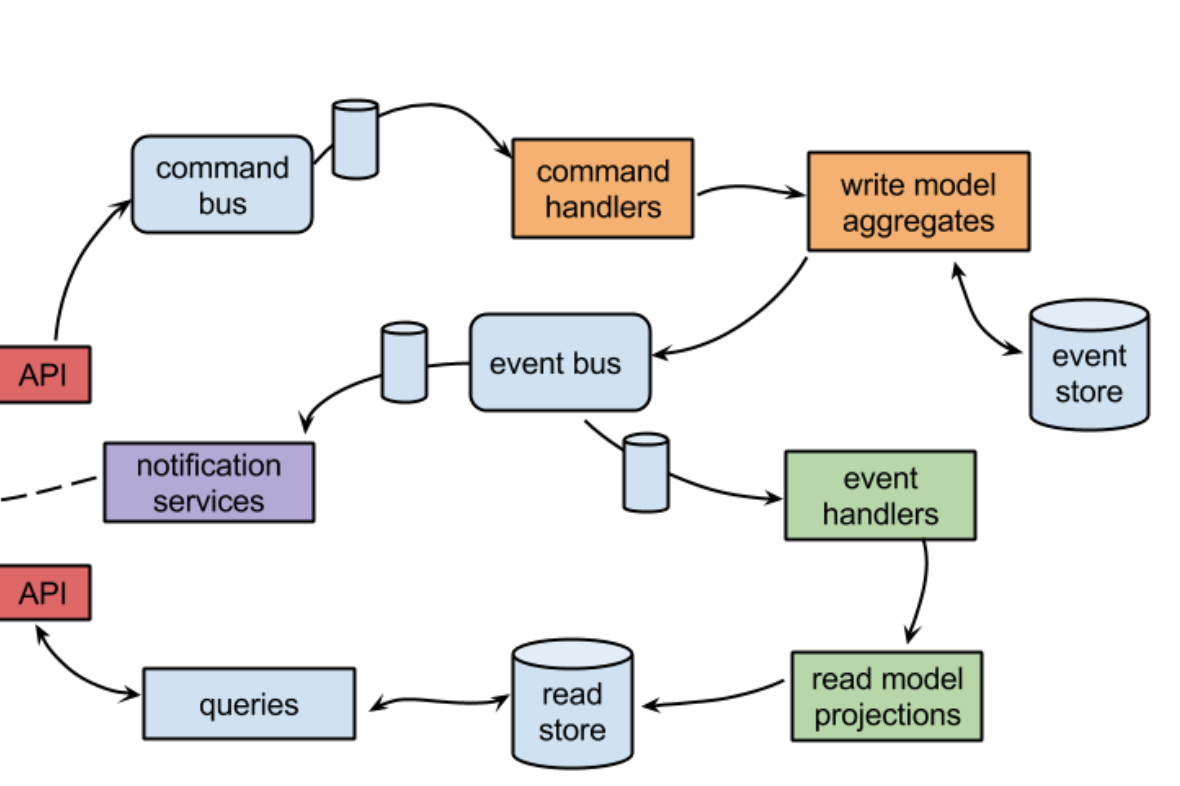
The CQRS pattern was introduced a while ago and made famous on the context of Domain Driven Design. It stands for Command Query Responsability Segregation and the idea is pretty simple: split the read and write responsabilities. When we follow this pattern our conceptual business domain model is required to have separate models both for update and display.
The concept should not be confused with Event sourcing, which we tend to see together, but strictly speaking is not necessary to have.
For example,if we think in the typical service that provides a set of CRUD features, a very naive approch would be just to split the service in two, separating read from write operations. No event sourcing required so far.
Event sourcing really mean that any change that happens on our application is tracked as an event in a sequential manner. By storing those events, the system will allow us to travel in time (Back to the future style), rewinding to a point and get a snapshot about how was the system before a event happened. The events provides with a full story on what has happened to our model across time.
Having two separate models leads obviously to eventual consistency issues as you need to have both in sync. One of the drawbacks is that adds an extra layer of complexity to our system and can open a can of worms.
If is complex… when can we apply it?
Martin Fowler recommends its usage with extreme caution, only when bounded context on complex business domains are available. So really you must be 100% sure that the risk is worthy the value you get from it.
Possible Use Cases:
-
The queries over the original data structure are too complex, or CPU time consuming leading to a bad performance. If we want our end users to have a nice experience we may flatten or denormalize its data structure into something which is optimized for that purpose. Common use cases are indexing the information into a easy to search format, using SOLR or Elastic Search.
-
The queries are accesed by many client (think on a REST endpoint). Our “update” command operations could be handled by a backoffice application which does not require too much resources, but if we want to scale our service accordingly we can focus only on the “read” query bits. Allowing to scale our application independently brings benefits on those apps where there is a huge difference on the traffic received for queries vs the updates.
Quick update on Eclipse IDE
Before we start digging into code, reviewing the awesome Micronaut guides, I see with joy that NOW we can run our Micronaut apps using Eclipse (in release 1.0.0.M2 only Intellij was fully supported).
Just installing a version 4.9 or above did the trick. Do not forget to install M2Eclipse for Maven and Maven integration with Eclipse JDT Annotation Processor Toolkit.
A simple CQRS implementation
Our example will handle the creation of movies in a CQRS scenario so we can see how the responsabilities are separated
Let’s assume we have two different data stores - one for updates and other that will act as agregate source for reads. Both of them would be really simple in-memory maps.
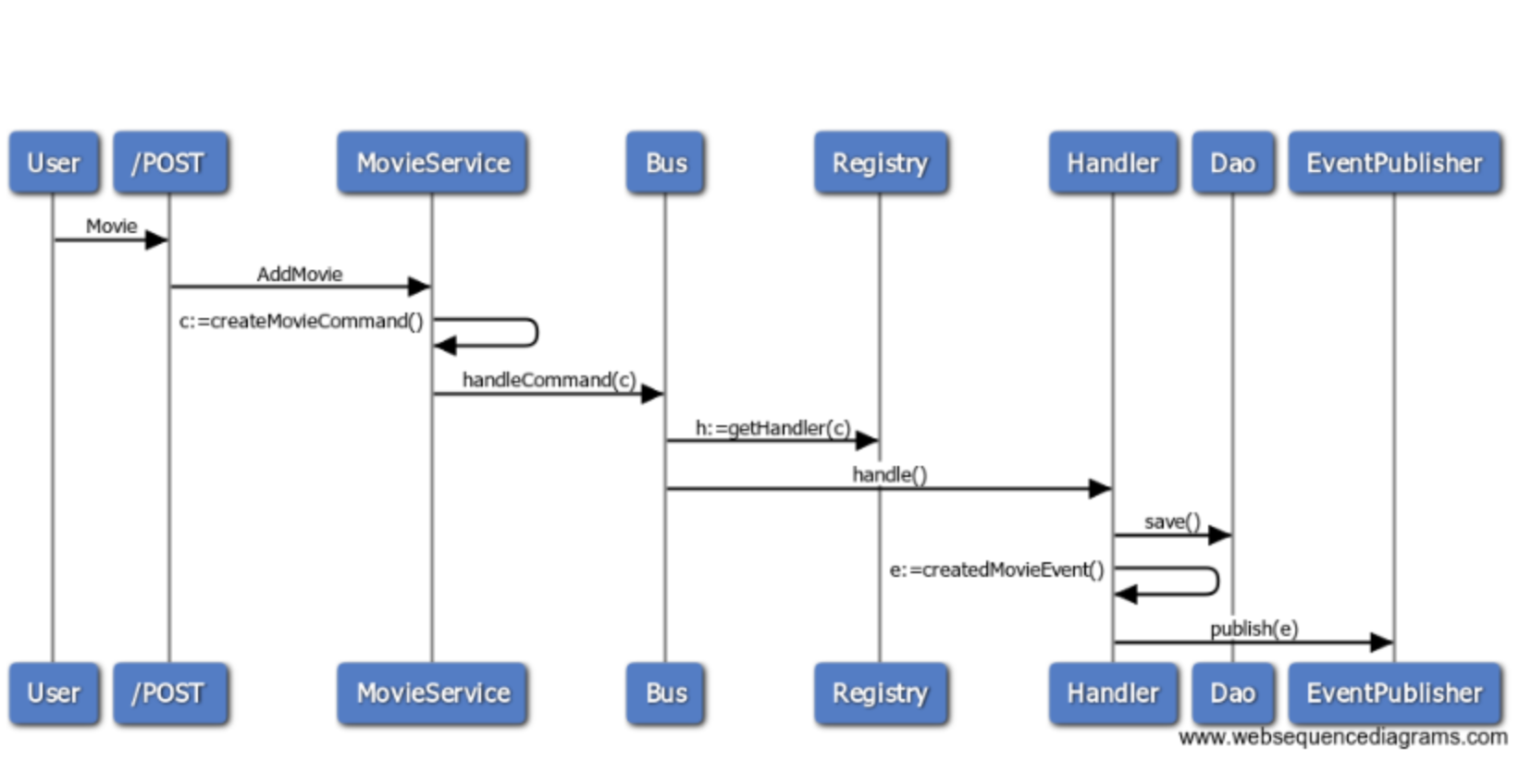
The following diagram explains how movie data is persisted in the first data store.
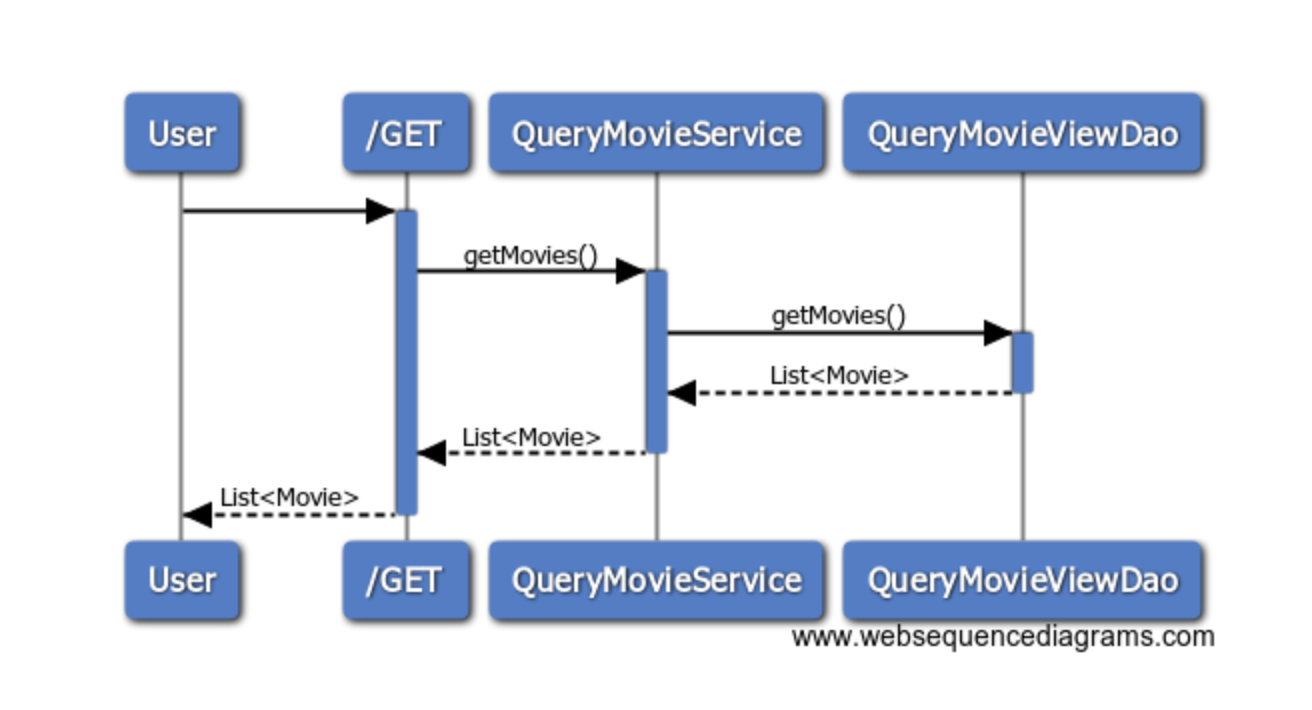
The following diagram explains how data is queried from the aggregate datasource.
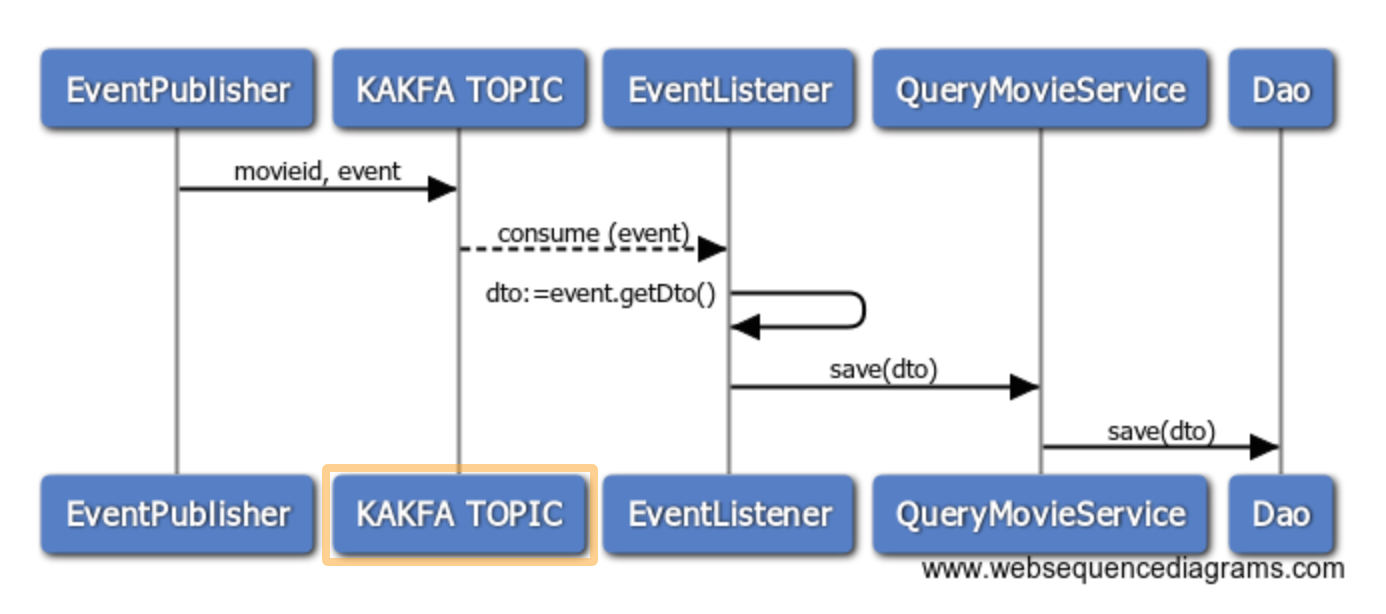
Ummmm… are not we missing something?How is possible that we can read from the agregate datastore? where did the agregation step happened? See below
REST endpoints
Usually you would implement a single endpoint to expose CRUD functionalities. However we will split our endpoint in two, to separate responsabilities
- POST /movies-write
- GET /movies-read/all
In a microservice world, it might make sense to refactor the application in two different apps, so we can scale the read service at will, but i will let that to the reader.
Services
You will not be surprised if the read service delegates to a DAO in order to retreive the movies.
However the behaviour of our write service is slightly different. It will just dispatch a new command CreateMovieCommand using our bus.
public class MovieService {
@Inject
private Bus bus;
public void addMovie(Movie m) {
bus.handleCommand(new CreateMovieCommand(m));
}
}
Command & Command Handlers
A command defines an abstraction of an action that needs to be done in our system (Create a movie)
The main responsability of a command handler is:
- persist the record associated to our command using a Dao.
- publish event indicating that the movie was created.
The Dao implementation uses just a simple in-memory List.
An abstract class defines a template in order to make easy implementation of custom handlers.
public abstract class AbstractCommandHandler<T> implements CommandHandler<Command<T>, T> {
protected static final Logger LOG = LoggerFactory.getLogger(AbstractCommandHandler.class);
protected Dao<T> dao;
private EventPublisher<T> publisher;
public AbstractCommandHandler(Dao<T> dao, EventPublisher<T> publisher) {
this.dao = dao;
this.publisher = publisher;
}
@Override
public Result<T> handleCommand(Command<T> command) {
T dto = getDto(command);
save(dto);
publish( buildEvent(dto));
return buildResult(dto);
}
abstract void save(T dto);
abstract T getDto(Command<T> command);
abstract AbstractEvent<T> buildEvent(T dto);
void publish(AbstractEvent<T> event) {
if (event != null) {
publisher.publish(event);
}
}
abstract Result<T> buildResult(T dto);
}
The bus
The only responsability of our bus is to find which is the handler associated to the command receieved and invoke its processing. A simple registry keeps track of relation between command and its handler. I implememented a one to one relation but there is no reason why we cannot use multiple handlers chained together to be executed in sequence.
public class BusImpl implements Bus {
protected static final Logger LOG = LoggerFactory.getLogger(BusImpl.class);
private Map<String, CommandHandler<?, ?>> handlers = new HashMap<>();
@Inject
public BusImpl(CommandHandler<Command<Movie>, Movie> handler) {
handlers.put(CreateMovieCommand.class.getSimpleName(), handler );
}
@SuppressWarnings("unchecked")
public <R> Result<R> handleCommand(Command<R> command) {
LOG.debug("handle command: " + command.getCommandName());
CommandHandler<Command<R>, R> handler = (CommandHandler<Command<R>, R>) handlers.get(command.getCommandName());
if (handler!=null) {
return (Result<R>) handler.handleCommand(command);
} else {
return null;
}
}
public <R> void registerHandlerCommand(Command<R> command, CommandHandler<Command<R>, R> handler) {
handlers.putIfAbsent(command.getCommandName(), handler);
}
}
Event publisher
You can browse micronaut.demo.cqrs.event.client to find out two implementations:
- Based on micronaut extending from io.micronaut.context.event.ApplicationEventPublisher Only valid for development purposes relying on single node deployment
- Kafka based, more robust and the focus of what I really wanted to test
Micronaut shines again to make our life easier. Providing Kafka connectivity can be achieved easily just declaring an interface with a annotation. Micronaut will generate the client for us, so we can inject it in our class
@KafkaClient
public interface EventClient<T> {
@Topic("movies")
void sendEvent(@KafkaKey String movieId, @Body AbstractEvent<T> movieEvent);
}
@Primary
public class KafkaPublisher implements EventPublisher<Movie> {
@Inject
EventClient<Movie> eventClient;
@Override
public void publish(AbstractEvent<Movie> event) {
eventClient.sendEvent(event.getEventId(), event);
}
}
Event listener
Identically to the publishing side of things there are two implementations in order to consume the events. I will show only the Kafka one
@KafkaListener
public class CustomEventListener {
protected static final Logger LOG = LoggerFactory.getLogger(CustomEventListener.class);
@Inject
private QueryMovieViewDao dao;
@Topic("movies")
public void consume( @KafkaKey String movieId, @Body MovieCreatedEvent movieEvent) {
LOG.debug("KAKFA EVENT RECEIVED AT CUSTOM APPLICATION LISTENER");
dao.save(movieEvent.getDtoFromEvent());
}
}
A note in the implementation
The example is a simple and naive approach, where some shortcuts have been applied in order to focus exclusively on the CQRS pattern. Some of the gotchas are:
- There is no transformation from domain into dto into persistence layer.
- The agregation only consist of persisting the same record in the second datastore. Good use cases would be flattening a complex domain model into a flattened view optimized for queries.
- In memory store is not a good idea once you add multiple instances of the same microservice
- There are no tests (and luckily it worked at the first try!)
- The handlers registry could be dramatically improved using anotations. Ideally we would like a @CommandHandler annotation that we can link together with the Command itself. The same would be ideal for handling of events.
How can we test it?
See the application.yaml on how everything has been configured Our application will start on port 8083 and will try to connect into a local kafka running on port 9092
kafka:
bootstrap:
servers: localhost:9092
micronaut:
server:
port: 8083
application:
name: movies
First of all we need to set up a local Kafka
We create a private network
docker network create app-tier --driver bridge
We will use that network so Kafka can see our Zookeeper server just using the name we declared while starting it.
Start our Zookeeper instance:
docker run -d --name zookeeper-server \
--network app-tier \
-p 127.0.0.1:2181:2181/tcp \
-p 127.0.0.1:2888:2888/tcp \
-p 127.0.0.1:3888:3888/tcp \
-e ALLOW_ANONYMOUS_LOGIN=yes \
bitnami/zookeeper:latest
Start our Kafka server:
docker run -d --name kafka-server \
--network app-tier \
-p 127.0.0.1:9092:9092/tcp \
-e KAFKA_ZOOKEEPER_CONNECT=zookeeper-server:2181 \
-e ALLOW_PLAINTEXT_LISTENER=yes \
bitnami/kafka:latest
We can trigger a Kafka manager so we can see what is going on in our cluster
docker run -d --name kafka-manager \
--network app-tier \
-p 9000:9000 \
-e ZK_HOSTS="zookeper-server:2181" \
-e APPLICATION_SECRET=letmein sheepkiller/kafka-manager
As we are running now in a private network, it does not allow us to access using localhost nor the name of the container. We need to find out which is the hostname assigned by docker.
That can be easily retrieved inspecting our container
$ docker inspect kafka-server | grep Hostname | grep -v Path
#Output
"Hostname": "89cc3866239e",
So we configure our our /etc/hosts mapping that entry with localhost
##
# Host Database#
# localhost is used to configure the loopback interface
# when the system is booting. Do not change this entry.
##
127.0.0.1 89cc3866239e localhost
::1 localhost
Once we have done we can start our application
mvn exec:exec
We create a movie
curl -d '{"id":"1111", "description":"A movie"}' -H "Content-Type: application/json" -X POST http://localhost:8083/movies-write
And we can retrieve it
curl -d -H "Content-Type: application/json" -X GET http://localhost:8083/movies-read/all
As usual all the Source code can be found here: Source code in github
Issues with Kakfa ?
Well, unfortunately I raised an issue in the gitter channel and later in github. Issue was related with the way KafkaBinder bindings body objects See Issue raised here
The team quickly fixed it and is available in 1.0.1 release. After updating my bom materials dependencies to 1.0.1, I still see that the message is not sent to Kafka.
Still more digging required … but in order to circumvent the issue I have provided an alternative implementation (kakfa free), so you only need to:
-
remove the @Primary annotation from the class KafkaPublisher and add the annotation to AppContextPublisher
-
remove the @Primary annotation from the class KafkaCustomEventListener and add the annotation to MovieEventsListener