Understanding AWS Elemental MediaConvert
Quick summary on AWS Elemental MediaConvert announced recently in Amazon ReInvent:2017
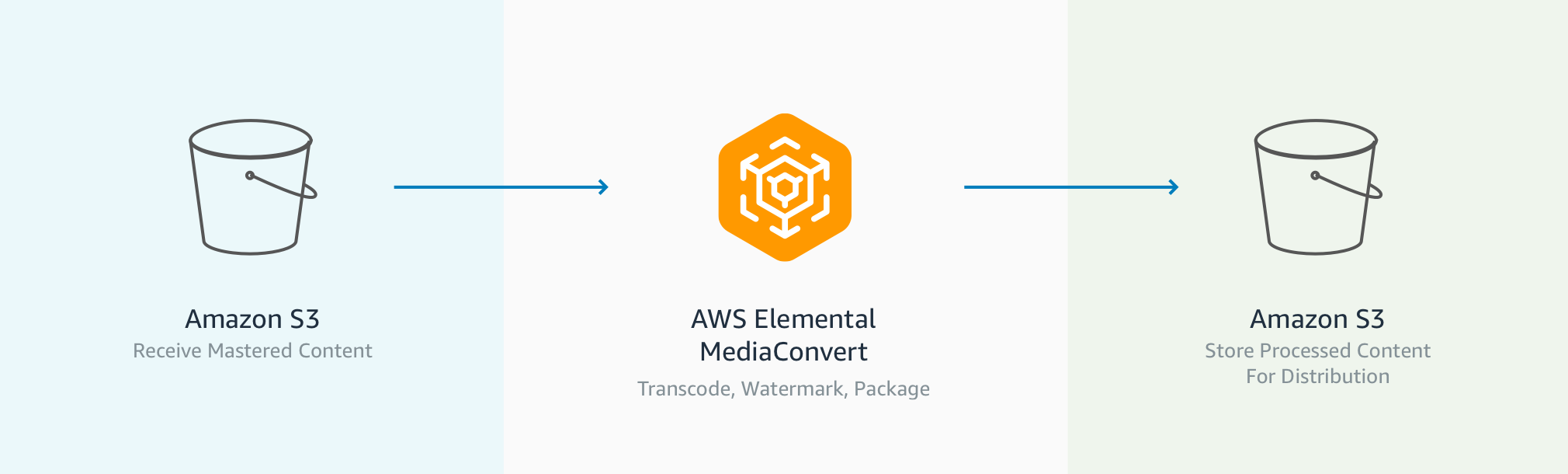
File-based video transcoding workflow. Which is the problem?
If you are not familiar with what file-based video transcoding is I will try to summarise describing which is the problem Broadcast distributors need to create different version of the input source. The video input source tends to be mezzanine content (high-quality studio masters) but sometimes can be the feed of a camera or even the video output produced by any recording device (welcome social media!).
The compressed version aim to reduce its size or format (including scaling) so is compatible with a set of device where the broadcaster aims to distribute its content (i.e: XBox, Web, Android, IOSm Smart TVs, etc). .
Other features related with video transcoding workflow are around adding graphic overlays, content protection, multi-language audio, closed captioning support, and professional broadcast formats. The following diagram explains
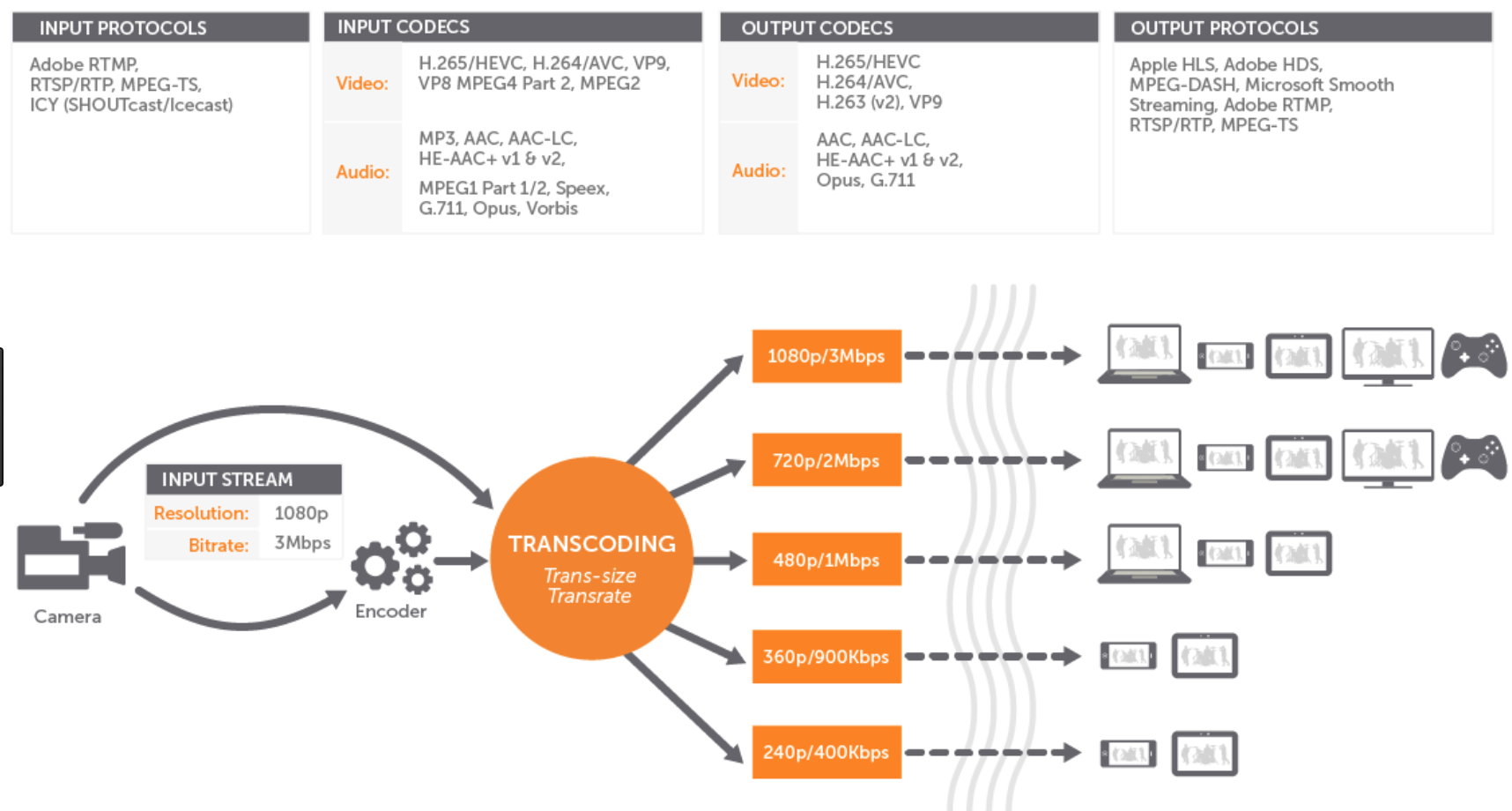
If you were to solve that problem on your own you would go either coding your self a wrapper of ffmpeg linux command tool or you will use some of the existing cloud APIs like Zencoder or encoding.com. Other alternative could be use Gstreamer which is also a python wrapper of ffmpeg that enables linux pipes style chaining of commands.
If you are here searching for an academical definition of transcoding is the process of taking digital media, extracting the tracks from the container, decoding those tracks, filtering (e.g. remove noise, scale dimensions, sharpen, etc), encoding the tracks, and multiplexing the new tracks into a new container.
How AWS MediaConvert works ?
AWS bought a couple of years ago the company Elemental who was specialised in the on-premises transcoding solution sector of media assets. Now AWS has integrated the product with its cloud offer and enable cloud transcoding in an efficient and pay per usage model to media companies.
With AWS MediaConvert you can create a job definition where you can specify
-
Input file :
Location of S3 input video file We can specify audio tracks and captions that live in our input file. In AWS terminology this is called “Selectors” -
Output :
Multiple output groups can be defined.
Multiple output groups? why?
In the previous section we saw that a job is made of one or more multiple groups. Which is the use case ? Why multiple output groups?
Imagine we want to distribute content both to different devices… in fact a common case due to the fact that broadcasters want to maximise revenue by following the “TV anywhere” premise. So you can see each output group as a set of settings that will enable rendering the video using a streaming protocol.
For each of these output groups we need to specify the location of S3 output file and the type of output we want.
- We can chose among (Combined files, HLS, DASH, Microsoft Smoot streaming)
- We can add video, audio and captions to each output group.
- Setting for each option are endless, so I will mention some of the more important settings that can be applied to each group
- Video stream settings like coding, resolution, scaling, sharpness, timecode insertion, framerates
- Video Setting related with manifest, codecs, ads insertion, SCTE-35 markers, DRM encryption, etc
- Video Preprocessor like input cropping, image insertion, color corrector, deinterlacer,noise reduction, etc
- Audio settings like codec, bitrate, sample rate,etc
- Audio remixing or audio normalizations
Jobs are nothing till submitted to a Queue. After job submission they are processed strictly in the same order the jobs were submitted. If we are interested jobs can be prioritised defining queues with higher priorities. In fact is a common practice to define a high priority queue to process urgent jobs and leave the default queue for ordinary jobs. At any time a job can be paused and restored at will.
The workflow can be improved by adding notifications to SNS topics once the S3 output file is written so users could receive emails about the completion status.