AWS Datasync Transfer service
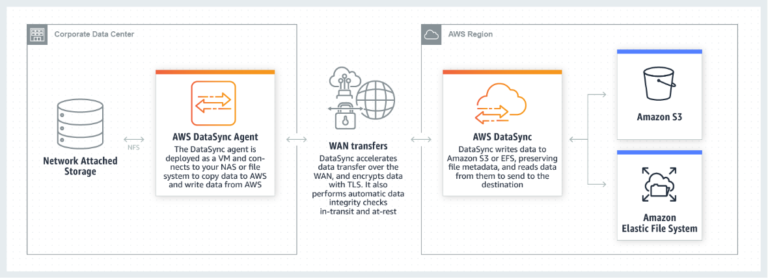
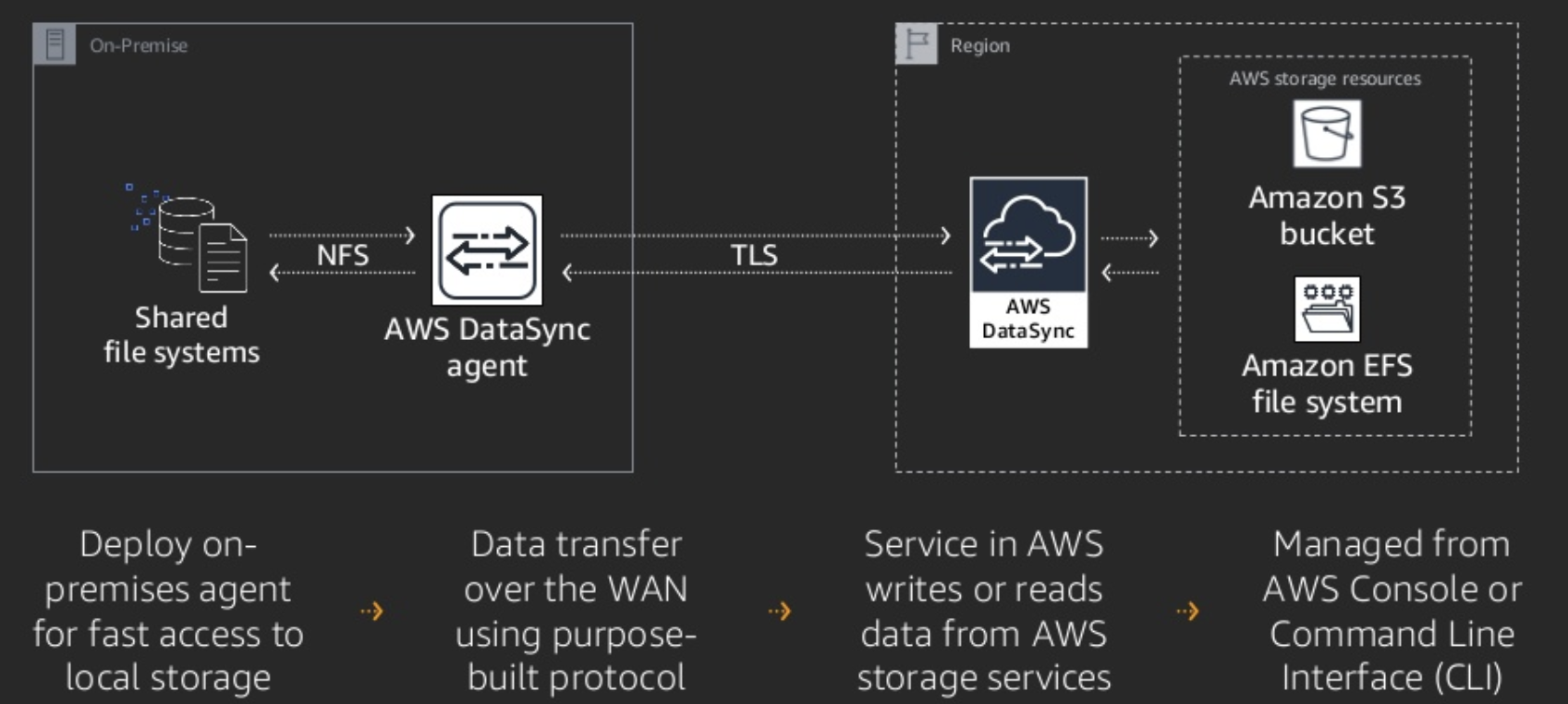
What is AWS DataSync
Datasync uses agents in order to transfer big amounts of data across different locations. Each agent uses tasks to perform the transfer and history of executions is attached to each task.
Data is encrypted in transit via TLS 1.2
The supported locations are
- Network File System (NFS)
- Amazon Elastic File System (Amazon EFS)
- Amazon Simple Storage Service (Amazon S3).
- SMS Network Shares (supports the Server Message Block (SMB) protocol)
Agents
An AWS Datasync agents needs to be running either on on-premises VMware ESXi hypervisor or Amazon EC2.
The agent uses service endpoint which might be public. However if security is a concern a better option is chosing VPC endpoints so the communications happens between DataSync and AWS services using the private VPC.
The agent is responsible of executing a task which defines which are the source and target locations among other configuration settings.
Our setup includes Auto Scaling Groups of EC2 instances. Each EC2 instance is provisioned in such way that it autoregisters itself against DataSync. A startup shell script performs a set of actions using aws cli:
- Get an activation key token
- Create an agent using the ip of the VPC subnets where our EC2 was attached to.
- Create a mount location (EFS/NFS/etc)
In an ideal world Agents will be online all the time, but there are scenarion where maybe the EC2 is terminated or paused where it becomes Offline.
Once we have our agent we can start creating tasks, choosing our source and target destinations Imagine from example using a S3 source bucket and as destination an EFS mounted as we described previously. Nothing of this is possible while the agent is Offline.
We can submit multiple tasks to a single agent, and take benefit of a FIFO like queueing approach
Tasks and executions
Tasks goes through different states

One particularly interesting is UNAVAILABLE which happens when our agent becomes Offline.
Once the task starts doing his job, detects changes, and transfer them from your source storage system to the destinations.
There are multiple setting for the task which determine:
- How the files are transferred
- Decide whether they keep metadata such us timestamp, file permissions, etc.
- Configure if we want to verify correctness of our transfer (checksum comparison)
- Configure if we want to keep the source files or remove them
- Allocate specific bandwith limits
The transfer job tasks can be configured using filters (inclusion / exclusion) so we can do selective transfer instead of simply just syncronizing two directories. Give us flexibility to cover multiple escenarioa like removing specefic subsets from our sources.
In case we define scheduling of task, we would end up with multiple executions, otherwise a task would be linked to a single execution.
History of executions is attached to each task, and old tasks remain available forever.
If the number of tasks & executions per day is big, probably is a good idea to
create some housekeeping job that periodically removes tasks to be sure that only the last X days/weeks period execution are retained.
Only existing executions related with a task can be cancelled, however is not possible to remove past executions associated to a task.
Monitoring
The task can be configured to use Clod Watch Log group to trace metadata relative transfers at a given time (name, size, and timestamp for each transferred file or object.), as well as the results of the content integrity verification performed by DataSync.
Management
Costs: In temrs of cost, we pay only based on the the data copied. 0,0125 USD per gigabyte (GB)
Datasync offer different perspective of metrics: per agent and per transfer task
- By Agent: Bytes Transferred, Bytes written, Files Transferred
- By Task: The ones available for agent plus metrics related to stats about files and bytes per source and destination
As any other service, cloudwatch log groups keep track of Datasync activity
Use cases:
- Data Migration
- Data replication / Incremental transfer
- Centralized resources
- Transfer of large datasets (media files)